
Vault 8: Hive
WHISTLEBLOWING - SURVEILLANCE, 13 Nov 2017
WikiLeaks – TRANSCEND Media Service
Vault 8: Source code and analysis for CIA software projects including those described in the Vault7 series.
This publication will enable investigative journalists, forensic experts and the general public to better identify and understand covert CIA infrastructure components.
Source code published in this series contains software designed to run on servers controlled by the CIA. Like WikiLeaks’ earlier Vault7 series, the material published by WikiLeaks does not contain 0-days or similar security vulnerabilities which could be repurposed by others.
![]() Today, 9 November 2017, WikiLeaks publishes the source code and development logs to Hive, a major component of the CIA infrastructure to control its malware.
Today, 9 November 2017, WikiLeaks publishes the source code and development logs to Hive, a major component of the CIA infrastructure to control its malware.
Hive solves a critical problem for the malware operators at the CIA. Even the most sophisticated malware implant on a target computer is useless if there is no way for it to communicate with its operators in a secure manner that does not draw attention. Using Hive even if an implant is discovered on a target computer, attributing it to the CIA is difficult by just looking at the communication of the malware with other servers on the internet. Hive provides a covert communications platform for a whole range of CIA malware to send exfiltrated information to CIA servers and to receive new instructions from operators at the CIA.
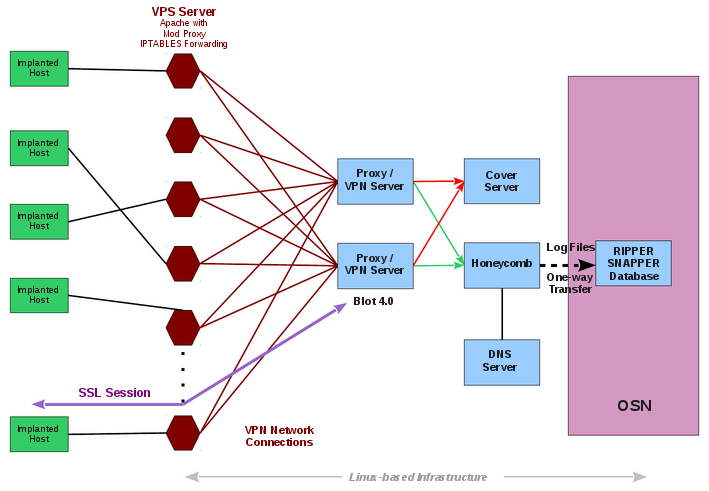
Hive can serve multiple operations using multiple implants on target computers. Each operation anonymously registers at least one cover domain (e.g. “perfectly-boring-looking-domain.com”) for its own use. The server running the domain website is rented from commercial hosting providers as a VPS (virtual private server) and its software is customized according to CIA specifications. These servers are the public-facing side of the CIA back-end infrastructure and act as a relay for HTTP(S) traffic over a VPN connection to a “hidden” CIA server called ‘Blot’.
The cover domain delivers ‘innocent’ content if somebody browses it by chance. A visitor will not suspect that it is anything else but a normal website. The only peculiarity is not visible to non-technical users – a HTTPS server option that is not widely used: Optional Client Authentication. But Hive uses the uncommon Optional Client Authentication so that the user browsing the website is not required to authenticate – it is optional. But implants talking to Hive do authenticate themselves and can therefore be detected by the Blot server. Traffic from implants is sent to an implant operator management gateway called Honeycomb (see graphic above) while all other traffic go to a cover server that delivers the insuspicious content for all other users.
Digital certificates for the authentication of implants are generated by the CIA impersonating existing entities. The three examples included in the source code build a fake certificate for the anti-virus company Kaspersky Laboratory, Moscow pretending to be signed by Thawte Premium Server CA, Cape Town. In this way, if the target organization looks at the network traffic coming out of its network, it is likely to misattribute the CIA exfiltration of data to uninvolved entities whose identities have been impersonated.
The documentation for Hive is available from the WikiLeaks Vault7 series.
Leaked Documents:
Go to Original – wikileaks.org
DISCLAIMER: The statements, views and opinions expressed in pieces republished here are solely those of the authors and do not necessarily represent those of TMS. In accordance with title 17 U.S.C. section 107, this material is distributed without profit to those who have expressed a prior interest in receiving the included information for research and educational purposes. TMS has no affiliation whatsoever with the originator of this article nor is TMS endorsed or sponsored by the originator. “GO TO ORIGINAL” links are provided as a convenience to our readers and allow for verification of authenticity. However, as originating pages are often updated by their originating host sites, the versions posted may not match the versions our readers view when clicking the “GO TO ORIGINAL” links. This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available in our efforts to advance understanding of environmental, political, human rights, economic, democracy, scientific, and social justice issues, etc. We believe this constitutes a ‘fair use’ of any such copyrighted material as provided for in section 107 of the US Copyright Law. In accordance with Title 17 U.S.C. Section 107, the material on this site is distributed without profit to those who have expressed a prior interest in receiving the included information for research and educational purposes. For more information go to: http://www.law.cornell.edu/uscode/17/107.shtml. If you wish to use copyrighted material from this site for purposes of your own that go beyond ‘fair use’, you must obtain permission from the copyright owner.
Read more
Click here to go to the current weekly digest or pick another article:
WHISTLEBLOWING - SURVEILLANCE: